
Web UI(AUTOMATIC1111版)を使ったAIアートの作り方を、覚え書きとしてまとめる。
ワンボタンで絵が作れるとはいえ、AIで自分の意図した絵を作るにはそれなりの工程が必要である。
もくじ
インストール
インストール方法や基本的な操作解説の記事は多くあるので外部リンクを載せる。
使い方
Features · AUTOMATIC1111/stable-diffusion-webui Wiki
NovelAI 5ch Wiki
↑ では指示語一覧だけでなく、既存キャラの生成方法や生成結果画像も紹介されている場合もあるのでわかりやすい。
UIの日本語化
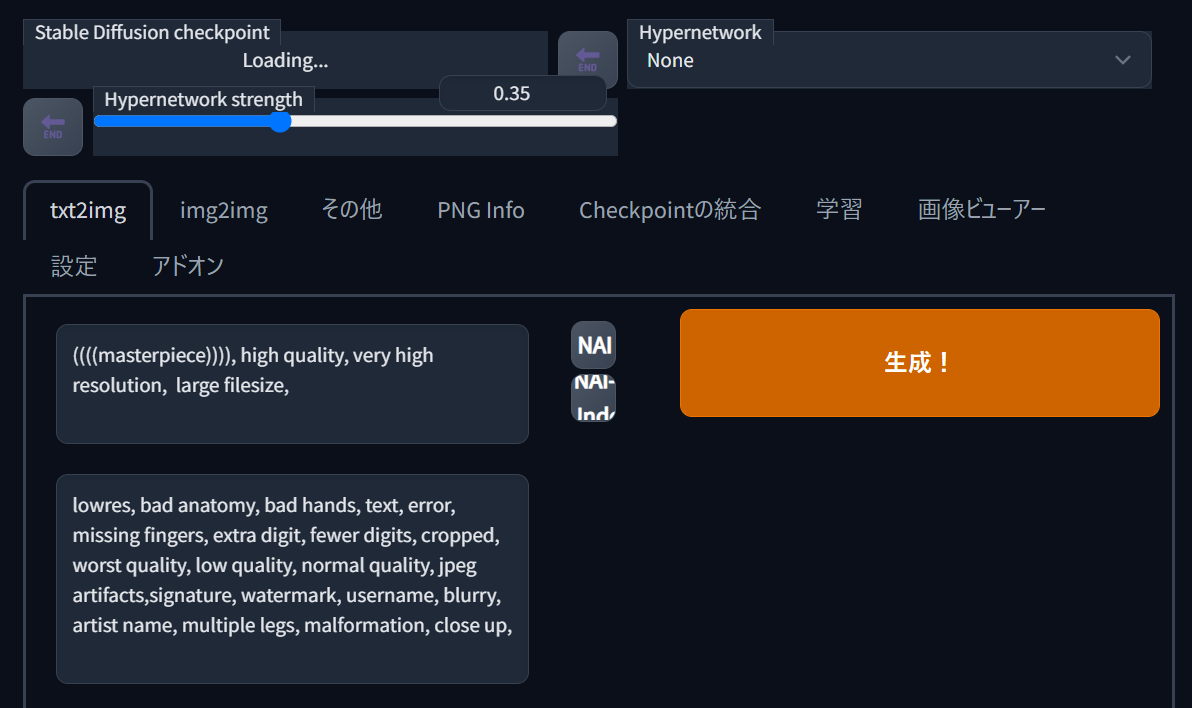
- Extensions > Available > Load From:をクリックする。
- Extension index URLが下記であることを確認
- https://raw.githubusercontent.com/wiki/AUTOMATIC1111/stable-diffusion-webui/Extensions-index.md
- 「ja_JP Localization」を探し、Installからインストールする。
- Installed > Apply and restart UIでUIだけ再起動する。
- \extensions\stable-diffusion-webui-localization-ja_JP\localizations\ja_JP.jsonから、内容を手動調整できる。
その他手動で追加
- 別途ja_JP.jsonファイルを入手し、/localizationsフォルダ内に入れる。
- WebUIを起動し、Setting > 「Localization (requires restart)」内から、先程のja_JPを選ぶ。
- WebUIを再起動する。
- 気に入らない箇所は自分で修正したり追加したりできる。
用途に応じてモデルを使い分ける
各モデルには必ず得意・不得意があり、特定のモデルだけで出せる絵には限界がある。
自分のほしい画風が得意なモデルをそれぞれ使い分けること。
また、txt2imgだけでなくimg2imgやインペイントでの部分修正を使い分け、それぞれの利点欠点を活かすとよりよい。
モデルのマージによりそれぞれの良さを取り入れることができる。(ただ少々難易度は高いので、初心者は配布されているモデルを使うのがよさげ)。
txt2imgから始める

プロンプトという指示テキストを元に画像を生成する機能。
画像生成のメイン機能であり、まずはこれで画像を生成していく。
設定は初期設定でもいいが、自分は下記でやっている。
- ステップ数:30step
- サンプラー:DPM++2M
- サイズ:縦長の512x768(キャラ立ち絵向け)
- サイズ:縦横の768x512(キャラや背景も魅せる絵向け)
- サイズ:縦横の1024x512(大人数やダイナミックな広い絵向け)
- 良い絵が出たらシード値を固定し、highres. Hix で倍サイズにし、ControlNetのcontrol_v11f1e_sd15_tileを利用して再生成する。
- img2imgに送って再生成してもよい。
プロンプト(呪文)を試行錯誤して欲しい絵のベースを出す
指示テキスト(プロンプト)や除外テキスト(ネガティブプロンプト)を試行錯誤する。
試行錯誤しながら、何度も生成することで良い絵を見つける。
最初の段階では大まかに欲しいキャラや構図を出すことを目指す。
この後のクオリティ上げ作業で、絵の微妙なニュアンス(表情・画風・ポーズなど)は変化してしまうので注意。
70%程度の出来の絵を出すつもりで、あまり気張らずにやる。
主に書き込む要素
- テンプレクオリティ上げ呪文
- ポーズ・アングル
- 人物(人数・性別・髪型・体型など)
- 表情
- 服
- 背景
- ライティング
- ネガティブプロンプトのテンプレ呪文
- 作成途中で邪魔になる要素は、ネガに追加
細かなテクニックの詳細はこちら。
シード値で、好きな絵をより作り込む
シード値を設定することで、大まかな結果を固定することができる。
プロンプトを試行錯誤して大まかに欲しいキャラや構図の絵を出すことができたら、そのシード値を使ってさらに絵を絵を煮詰めていく。
シード値はAI画像生成で重要であり、プロンプトや各種設定の影響力を実感しながら調整することができる。
ちなみに、AI画像は、実行時の各種設定がすべて同じならば、必ず全く同じ結果が得られる。
(モデル・embeddings・hypernetworks・setting・ステップ数・シード値・プロンプトなど)
シード値をコピーする
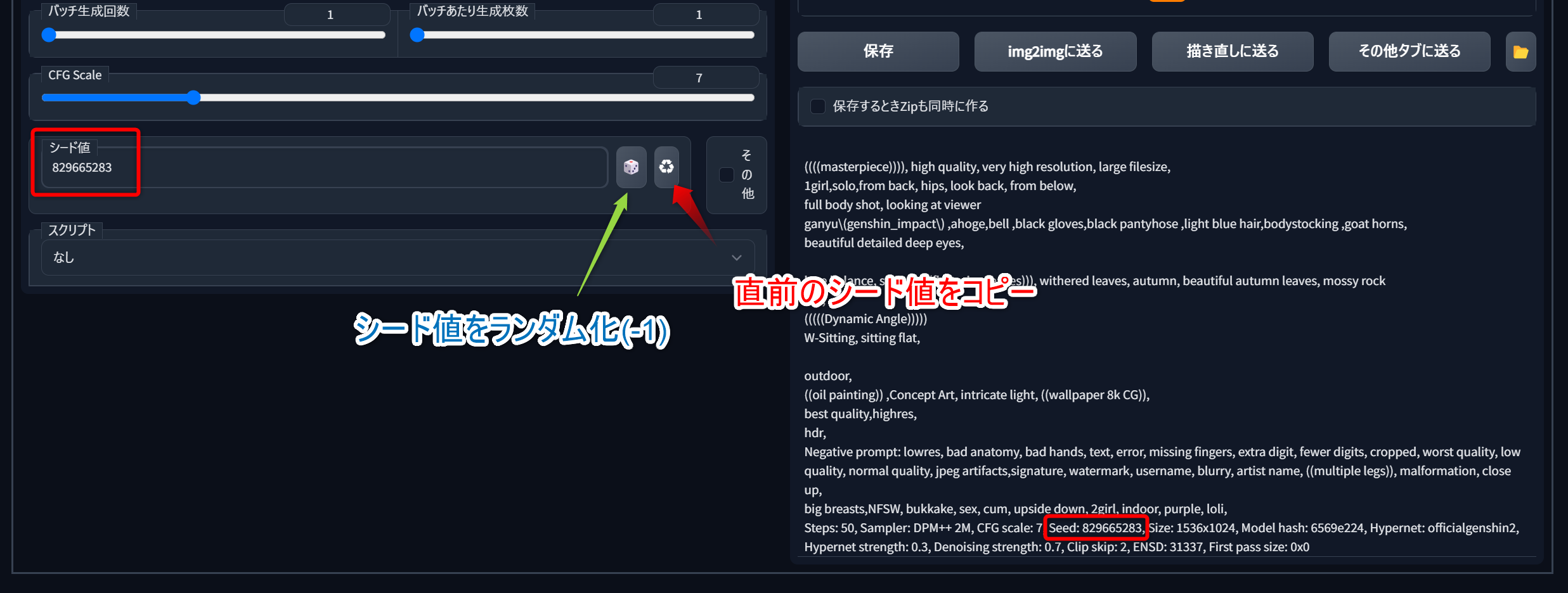
生成結果の情報テキストから手動でコピーしてもいいが、右のアイコンを使うと直前のシード値をコピーできる。
ちなみに、初期設定(-1)だとシード値が毎回変更されるため、毎回違う結果が出るようになっている。
後からシード値を確認する
シード値は画像データに含まれているので後からでも確認できる。
(生成後の画像をPNG Infoタブ内に投げ込む)
txt2imgの設定
基本設定のままでも問題ないが、より作り込みたい時は各種設定をよく理解して扱うとよい。
サンプラーの違い

サンプラーの使い方としては、「最初はDDIMやDPM++2Mなどの早いサンプラーを低解像度で回し、いい構図を見つけたらKarrasをいくつか試してみて好きな絵を見つける……」みたいな感じがよさそう。
特にこだわりがないならEuler系の絵が変わらないサンプラーを1つ決めて使えばよいか。自分はDPM++2Mを使ってみている。
画像の縦横比によって出る絵が違う
画像の縦横比によって、出やすい絵が違う。
欲しい構図にあった縦横比で生成するのは案外重要な模様。
- 縦長では人物1人を真正面から見た絵、立ち絵などを生成しやすい。
- 横長では複数人や横に寝ている人物の絵、背景が生成しやすい。
- さらに横長にすると、より多くの人物がいる絵を生成しやすい。
クオリティを上げる


プロンプト
high quality, very high resolution, large filesize, original illustration, ultra detailed illustration, resin art,
((serious)),
[[full body shot]], ((dynamic angle)), [[jumping]],
music live, have a mike, singing, girl on the stage, high detailed Background, Large audience and psyllium light,
blue lighting,
[[hatsune miku]], Beautiful face, ((cool girl)),(seriously face), hair ornament, small breasts, slender,
blue hair, very long twintails, fluffy hair, messy hair, floating hair,
beautiful detailed deep eyes,
dress, white dress,very short skirt,Pannier skirt, frill, off shoulder, white sox,detailed clothes, classy and elegant clothes,
dynamic lighting, Rembrandt lighting, hdr, colorful refraction, overexposure, [lens flare], bloom, film Reflection,
((colorful Reflection)),
(beautiful detailed glow), light particles, light diffusion,
[chromatic aberration],
[[cyber effect]], light particles foreground,
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, multiple legs, malformation, close up,
big breasts, photorealistic, ((loli)), ((cute)), ((red))
Steps: 20, Sampler: DPM++ 2M, CFG scale: 7, Seed: 2055406783, Size: 1024x1536, Model hash: 6569e224, Denoising strength: 0.7, Clip skip: 2, ENSD: 31337, First pass size: 0x0
絵がいい感じになってきたら、それをベースに再生成することでクオリティを上げる。
方法はいくつかあるが、どの方法でも印象は若干変わってしまう・必ずしもより良い結果になるわけではないので注意。
- txt2imgで、プロンプト煮詰める。
- "Highres. fix"を有効にすること。
- よさげな生成結果を得たら、txt2imgで高ステップ数・倍サイズ化で生成する。
- 倍化でうまくいかなかった場合は、img2imgに投げる。
- サイズ倍化・ノイズ強度0.5~0.7程度で調整してみる。
- img2imgは、低い値なら元絵を保持しやすいが、ディティールが死にがち・元絵以上のディティールを追加しようとするとノイズ強度を上げる必要があり、ノイズ強度を上げると元絵の構図から離れてしまうのが難しい所。
いくつか試してみて、より良い結果を見つける。
img2imgでサイズ倍化かつノイズ強度0.5程度なら、かなり元絵を保持したまま高解像度化できる。
解像度を上げる
サイズを上げて高解像度で生成する。
高サイズほど細部を細かく書き込んでくれる。
毎回高画質生成するのは生成コストが重いので、欲しい印象が固まってきて、いい感じの絵が当てられたら高画質生成を試してみること。
- 比率は変えないこと。画像比率も構図が変わる要因になる。
- 512x768なら、倍の1024x1536。
- 上げ過ぎると崩れる?
- 最大の2048にすると、"Highres. fix"でもディティール過多で顔が崩れてしまう。
高サイズの生成では、"Highres. fix"を有効にする
高サイズで生成すると、複数人・複数アングルが混ざった絵ができてしまうことがある。
Highres. fixオプションを使うと、大まかな構図を固めてから生成するので、構図が混ざることを回避することができる。
(低いステップで作った絵を元にimg2imgするように生成される)
- 値が低すぎるとボケた絵になる。
ステップ数を上げる
ステップ数を上げることで細部を描画させる。
30step程度を試してみる。
ステップ数でのディティール向上を考えるなら、絵が変わらない系サンプラーを利用すること。絵が変わる系ではこの方法は使えない。
(DDIMやDPM++2Mなど。ステップ数の項目を参照)
必ずしも「ステップ数は高ければ高いほどいい」というわけではないので注意。
- 大体20step程度で構図が安定していく。
- 大体80stepなど高いステップ数になると、それ以降変化が見られないようになる。
- (結果が収束する)
- しばらく使ってみた結果、自分としては30step程度でも十分かもしれない。
img2imgで解像度・ステップ数を上げる
Denoising Strengthが低いほど元絵の印象を保ったまま再生成できる。
ただ、単にやるだけではディティールが潰れる。
下記のControlNetを利用することで、印象そのままに解像度上げできる。
ControlNetで構図を固定する
拡張機能の「ControlNet」を利用することで、生成する絵を別の画像で制御できる。
これに高解像度化したい元画像をそのまま設定することで、ノイズ強度が高すぎると起こる変形やポーズ変更・奇妙な描画の追加がなくなって、元絵通りの構図のまま高解像度化することができる。
- ControlNetをインストールする。
- control_canny-fp16をダウンロードしておく。
- WebUIのUIを再起動する。
- txt2imgやimg2imgの画面左下にControlNet v1.1.150などという項目が追加されるので、開く。
- 下記の設定して実行する。
- Enableで、影響を有効化する。
- Preprocessor(利用する制御タイプ)に、「canny」を設定する。
- モデルに、control_canny-fp16を選択する。
- Control Weightに、影響度を設定する。
(0.5~0.7くらいがよさげ?なるべくそのままがいいのなら1.0)
*ControlNet1.1 Tile が凄すぎて語彙力|BD|pixivFANBOX
img2imgで、良い構図から別の絵を再生成する

txt2imgでゼロから作るよりも、img2imgを利用してある程度構図が決まった状態から生成させると意図したものを作りやすい。
特に複雑な構図を作るときは、手書きの下絵の方がうまくいく。
例え絵が下手でも作りたい絵が既に決まっているなら、大雑把なラフ絵を自分で用意してimg2imgで生成していった方がうまくいきやすい。
また、txt2imgで生成した良い感じのものを、こちらでさらに再度生成するというやり方もよい。
Denoising Strengthの値について
img2imgでは、元絵にノイズを加えて、AIがそれをベースにノイズを除去するようにして別の絵を出す。
そのため、Denoising Strengthで加えるノイズが低いほど元絵に近く、強いほど別の絵が出やすい。
0.1~0.4程度だと、かけたノイズを除去しきれていないため、潰れた絵になる。
0.5程度だと、元絵からあまり変化しない高解像度絵になる。
0.7程度だと、大まかな構図が似た別の絵になる。
1.0程度だと、別の構図の絵になる。
簡易ペイントツールが使える

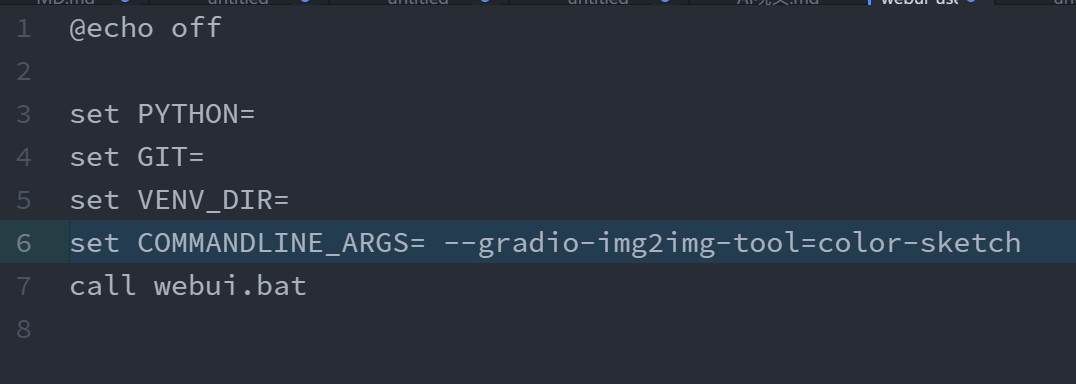
デフォルトではないので、自分で有効化することで使用できる。
かなり簡易的なペイントツールだが、すぐに大雑把に修正したい時はよさそう。
ただ、ショートカットキーもないので、外部ペイントツールに慣れているなら外部を使った方が楽だししっかり修正できる。
- webui-user.batをテキストエディターで開く。
- call webui.batより上に、下記のコマンドを追加する。
- 外でもset COMMANDLINE_ARGS=を使っているなら、それに続いて「set COMMANDLINE_ARGS=--a --b --c」のように書く。
- WebUIを再起動する。
set COMMANDLINE_ARGS=--gradio-img2img-tool=color-sketch
インペイントで、部分的に修正する

目や手・飾りなど、部分的に気に食わない箇所を修正することができる。
周りの絵を考慮しながら自動で特定の箇所を補完してくれる。
こちらも結果に振れ幅があるので、良い結果が出るまでデノイズ値を調整したり、繰り返し生成すること。
- img2img > Inpaint タブに切り替える。
- 画像生成に利用したプロンプト・ネガティブプロンプトを貼り付ける。
- ブラシモードになるので、修正したい箇所を塗る。
- 大雑把でも割と問題なく行ける。
手動で修正してからimg2imgを行う
書き込みや、ゆがみツールでの拡大縮小・選択範囲ツールでの切り貼りなどで、気に食わない部分を修正する。
img2imgで再生成するなら多少雑でも問題ない。
画像編集ツール(Affinity Photo)
高機能な画像編集ツールはやはりPhotoshopであるが、安くて買い切りが良ければAffinity Photoがよい。
Photoshop以外の画像編集ソフトでは不足している機能が一通り揃っている。
特にクリスタではできないきれいな選択ツールや、ちょっとしたゴミの自動除去などができる点が便利。
良い結果を部分的に手動で合成する

微調整中に良い結果が出たが細部の印象は前の方がよかった、ということがよくある。
その場合は、他の結果のいい部分だけを手動で合成すればよい。
同じシードで似たプロンプトの結果同士なら大きくレイアウトや色味が変わらないので、マスク合成だけでも自然に合成できる。
上画像では、顔や耳、背景の左部分・足元などを合成している。
AIの機能というわけではないが、様々なパターンが出せるAIの良さを活かせる。
- 外部ペイントツールにて、単純にほしい部分だけを手書きでマスクして、良い結果が出た別の画像に重ねる。
- 柔らかなブラシで塗るだけなので簡単。
- 画像を編集するため、アップスケールにHighres. Fixは使えなくなる。アップスケールにはimg2imgを利用する。
- ノイズ強度は0.5~0.6程度にすると元絵との変化が少ない。
- アップスケールした際に、部分的に元絵の方が良いこともよくあるので、これも同様に部分合成するとよい。
- 合成に使ったマスクも画像書き出しして、インペイント アップロードでそのマスクを使用すれば、部分的に修正しやすい。
イラストのキャンバスサイズを広げる
「いい絵が生成できたけど画像の縦横比が気に食わない」ということがある。
img2imgのインペイントを使って、存在しないキャンバスサイズを広げる方法を紹介する。
データにないアーティストの画風やキャラの特徴を追加する(embeddings/hypernetworks/LoRAなど)
画風ファイルを追加することで、元のモデルにはない画風や概念・キャラの特徴などを追加することができる。
hypernetwork Strengthを調整すれば元のモデルとhypernetworkの絵柄がミックスされるため、元となったアーティストの画風とも異なった絵を作ることができる。
生成画像を管理する
大量画像の整理は、Photo Scape Xを利用するとよい。
大量画像の高速一覧表示やレーティングができる。
画像ビューアーアドオンを使うと便利
stable-diffusion-webui-images-browser
今まで生成した画像を一覧で見ることができる。
PNG infoと同様に使用したプロンプトの確認や転送がすぐさまでき、データを振り返りやすくて便利。
- Extensions > Available > Load from: を押す。
- 一覧からImage browserを探し、インストールする。
その他の小ネタ

十字キーで設定変更
設定のスライダーは、設定が選択状態なら十字キーの左右でも操作できる。
値を細かく指定したい場合はこれで操作する。
Web UIを起動しやすくする
Web UI スタートメニューの登録することで、起動しやすくする。
このアプリを今後もよく使うようなら登録しておくとよい。
デフォルト設定を変えて使いやすくする(ui-config.json)
プロンプトやネガティブプロンプトでほぼ必ず使う定型文は、最初から追加されるように設定しておくとやりやすい。
サンプリング回数や幅・高さ設定も、自分のよく使う好みの設定にするとよい。
特に、WebUIを開き直したり、タブを再読み込みすると全ての設定が戻ってしまうので、デフォルト設定はなるべくすぐに始められる設定にしておくと楽。
- /ui-config.jsonをテキストエディターで開く。
- 下記の場所の""内に、好きな文章を追加する。
- "txt2img/Prompt/value": ""
- "txt2img/Negative prompt/value": ""
- "img2img/Prompt/value": ""
- "img2img/Negative prompt/value": ""
- ついでに縦サイズのデフォルト値を768に変えると、人物の生成がしやすくなってよい。
- "txt2img/Height/value": 768,
- "img2img/Height/value": 768,
- WebUIを再起動する。
NovelAI産プロンプトを変換するアドオン
プロンプト内の{}を、()に変換するボタンを追加する。
ネットで公開されているNovelAI産プロンプトを流用する時に地味に便利。
- Extensions > Available > Load from: を押す。
- 一覧からnovelai-2-localを探し、インストールする。
メニューデザインはユーザーCSSで調整できる
user.cssを使って、利用しない機能のメニューを非表示にしたり、レイアウトを多少調整することができる。
特に上項目の方法でヘッダメニューを増やすと画面半分にした時に占有率が高いので、ノートパソコンのような狭い画面では調整するとよい。
Extrasで、単純に画質を上げる
Extrasタブから、画像を単純に高解像度にすることができる。
各設定ごとに画質の上げ方に違いがある模様。
生成した画像の呪文を再度確認する(PNG Info)
いい感じの絵を生成できても、その呪文を忘れてしまうことがある。
PNG Info タブで画像を渡せば、生成した時の呪文と設定を確認することができる。
シード値を調べるのにも使える。
これは、ネットからDLしたAIアートのファイルでも確認できることがある。
(アップロード時に画像が変換されるサイトだと、埋め込まれた情報がなくなってしまうので確認できない)
ノートパソコンでは電源接続してやること
ノートパソコンのバッテリー駆動では生成しない方がいい。
電力を多く消費するし、低電力モードでは生成が遅くなる。
自分もノートパソコン環境なので、たまに生成が遅い原因が電源刺し忘れだったということがある。
ノートパソコンで生成する場合は、電源接続した状態で行う。
生成結果が黒画像になる
SDアップスケールなどで高解像度指定すると(?)、部分的に黒くなったり全部が黒画像になる問題。
いつかのアプデから起きる問題の模様。
下記の方法で解決する場合がある。
- webui-user.batファイルを、テキストエディターで開く。
- 「set COMMANDLINE_ARGS=」の後に、「 --no-half-vae」を追加する。
修正前
set COMMANDLINE_ARGS=修正後
set COMMANDLINE_ARGS=--no-half-vae
Maybe hint for black image bug · Issue #2830 · AUTOMATIC1111/stable-diffusion-webui
十字キー上下での(テキスト:1.0)設定機能を無効化する
テキスト選択しながらShift + ↑↓キーで、選択範囲のテキストを囲って値設定ができる。
しかし、このキーマップは通常のテキスト編集操作でも普通に使う操作なので誤爆してしまう上、やり直しできない。
この機能を無効化するには、下記ファイル内のテキストを削除か、「// 」でコメントアウトする。
\stable-diffusion-webui\javascript\edit-attention.js
見切れている絵の範囲を拡張する(Outpainting mk2)
うまく生成できた絵でも、脚が見切れていたり、頭頂が見切れてしまった場合がある。
これは、Outpainting mk2を使うことで、画面の外側の領域を生成することができる。
ただ、これではうまくいかないことも多いので、後述のように手動で拡張してインペイントした方が楽かもしれない。
- img2img >一番下の Script > Noneから、Outpainting mk2 に変更する
- 作った時と同じ呪文を使って生成する。
アプリのアップデート

git pull を使う
- アプリのフォルダーを右クリック > git bash here
- 開いた画面に、"git pull"と入力してエンターを押す。
Source Treeを使ってマージする
上記方法のgit pull ではエラーが出て失敗する場合は、Git管理アプリを使ってマージするとよい。
自分でWebUIのデータを変更した時にもマージする必要がある。
- Source Treeをインストールする。
- WebUIのフォルダーをSource Treeに追加する。
- "フィッチ"で、新しい更新内容だけを取得する。
- "マージ"で、追加された更新内容の最も上の項目を選択し、OKを実行する。
- もしコンクリフト(競合)が起きたら、適宜必要な方を優先して、更新内容を解決する。
- 自分がアプリの内容を編集しているとこのコンクリフトが起きる。
- 問題なければ自分の更新内容を優先してもよい。
リンク
感想についてはこちら。